昨天做ppt,并没有来得及写百天,今天下午终于把准备了一段时间的gil讲完了。
效果一般。
自己一段时间之内都有一个毛病,做分享或者演讲,经常是先做加法再做减法,先疯狂地阅读极多地文章,然后画一张巨大的导图,然后在在导图的基础上反思压缩,最后提炼出一篇文章或者ppt出来。
这样有一个很大的问题的。
自己一向比较贪婪,对于信息,对于书籍,对于知识,总是想囤积,收取,榨干。
所以经常做加法做到最后一刻,却不留下足够的时间去反思去消化,最后自己勉强明白了,告诉别人的时候却还是夹生饭。
Gil全称global interpreter lock,全局解释器锁,用来防止同一时间有多个线程访问字节码,也就是说同一时间,只有一个线程能够使用python解释器。
之前在学python的时候,不断有人告诉我,gil是并行计算的死敌,对于刚开始使用scikit-learn使用的很舒爽的孩子来说,告诉我一门机器学习很便利的语言在将来根本一无是处无疑是一种打击。
python目前的几种实现,pypy,jython,ironthon,cpython,其中jython实现在java虚拟机上,ironthon实现在net环境中,它们的线程同步由各自的虚拟机负责处理,从而可以免于gil这种奇怪的东西。
要讲gil,首先得说一下为什么要讲这玩艺。
一个实验。
def count(n):
while n > 0:
n -= 1
简单的程序,在单核单线程中,使用ipython来计时运行:
%time count(10000000);count(10000000)
Cpu time: user 986ms sys: 508 μs total 995s wall time: 1 s
使用双核双线程来运行,调用python的多线程包threading
%time t1=thread(target=count,args=(10000000,));t1.start();t2=thread(target=count,args=(10000000,));t2.start();t1.join();t2.join()
Cpu time: user 1.72s sys: 396 ms total 2.12 s wall time 1.26s
禁用一个核,即使用单核双线程来执行的时候:
Cpu time: user 978ms sys: 17.6 ms total: 995 ms wall time 1s
注意红字的奇怪结果,一个双线程的cpu富集型程序,在双核上运行反而比单核上运行要更慢。
这是什么情况,不是说双核能够提供真正的并发运算,使得多线程程序能够真正的同时运行,从而更快么?
这就就gil在做怪了。
对于gil产生的一切怪现状,时刻记得最重要的一点,python自身是不对线程做任何调度的,在python的线程实现机制中,没有优先级,没有抢断,没有轮转调度,这些比较”重”的操作,python都交给了操作系统来实现,而python自身,只负责很小一部分数据结构的记录等功能。
这些数据结构之中就有gil。
python在创建一个线程的时候,会为每一个线程创建PyThreadState这样一个数据结构,这个数据结构中包含了栈指针,调用的递归深度,线程id,还有一些debug,trace钩子之类的信息,
在python解释器中维护着一个_PythonThreadState_Current的指针,始终指向当前线程的PythonThreadState,
之后python调用PyEval_CallObject运行字节码,同时获取gil锁,保证同时只有自己在运行。
一个线程就这么跑起来了。
一、当gil遇到i/o操作
在gil锁的控制下,如果比如理想,那么一个线程开始运行,一直占用着cpu,世界如此美好,等到需要读文件,或者打印到屏幕之类的i/o操作的时候,线程就打开gil,然后阻塞往自己,去处理i/o请求,而打开的gil被其他的线程获取,从而其他的线程可以运行。
事情就这样成了。
这样看起来,在gil的控制下,世界仍然很和谐,大家谦让有方,相互帮衬着点,不失前核心所谓的,一个和谐的世界。
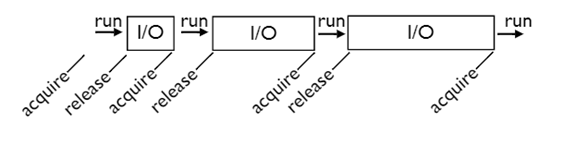
二、当gil遇到cpu bound型线程
假使一个线程在运算是的计算富集型的任务,那么事情虽然有些不妙,但是也还可以,python解释器会在每个线程被创建的时候,设置一个计数,称之为tick,这个计数是随着线程的运行而递减的,初始值是100,当减为0时,线程也同样发挥谦让精神,阻塞往自身,同时打开gil锁,并把控制权交给python解释器,python解释器运行一个check,检查是否有其他线程在等待gil锁。
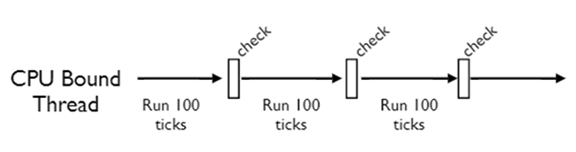
看起来,一切也还不错,人们仍然乐善好施,就算是自己吃饱喝足了,也不会忘记第三世界国家中还有很多黑人弟兄们等着我天朝的援助。
在事情变坏之前,让我们来谈,tick,check和signal。
未完待续。(预计三篇)