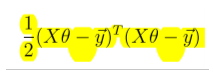
上节从最简单的随机变量扯到宇宙原理(汗)。今天接着上次扯。
关于均值,方差标准差什么的,没有什么好说的。
值得一提是书中提到的关于随机变量的变换,
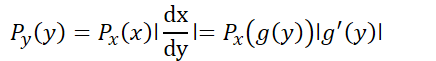
在满足x=g(y)的情况下,概率密度函数存在着变量的代换,这里比较需要注意的变量代换的下标。
离散型与连续型随机变量的期望公式,也比较简单,但是需要注意边缘分布与联合分布下的对某一随机变量的期望求解。
特别是条件分布的条件期望:
|
|
|
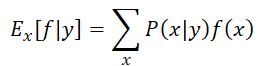
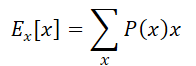
关于条件期望的形式,非常容易出错,貌似之前我经常写错f(x)的位置
这里需要记得,关于条件期望,是指首先是条件概率,即在条件y下x发生的概率,然后在x发生的情况下,再去对x进行函数变换。
上次本来说要好好谈一谈协方差,但是自己对协方差的理解感觉也需要演化,于是推一推,现在且先记得协方差衡量的是两个变量之间的相关性就可以了。
之后贝叶斯公式再次出现了,不过换了两个变量,变得得更有意义了
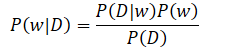
这里的w即是我们在机器学习过程中所需要优化和拟合的模型的参数,而D则是训练集。从贝叶斯的角度来理解,我们的目标是在给定了训练集的情况下,预测参数,也就是计算P(w|D),而根据等式的右边,我们可以通过对于P(D|w)的计算来完成,P(D|w)是指在给定的参数下,训练数据出现的概率。
也就是说,刚一开始,我们要优化的目标是看到数据,想一想,这样的数据可能对应着什么的参数,但是反过来思考,什么样的参数会产生这样的数据呢。
P(D|w)就是传说中大名顶顶的似然函数。
在贝叶斯学派和频率学派的做法,似然函数都起着非常重要的作用。
对于频率学派而言,w的值是固定,他的值,需要通过估计来求得,而估计的过程则需要考虑所有可能出现的数据集。
而对于贝叶斯学派而言,我们的数据集只有一份,即是目前眼前看到手中持有的那一份,因此参数的不确定性就表示为参数w的分布。
频率学派的做法一般是最大似然,即求maximize P(D|w),而通常的作法是求最大似然的负log值,这个负log值被称为error funcion,或者损失函数。
因为log函数是单调递减函数,因此最大似然,也就意味着最小错误。
在最简单的线性回归,如果我们最错误建模为是由于高斯噪声出现的,那么对高斯分布,进行反向log运算,再进行一些简单的变化后,就能够得到最常见的损失函数的形式。