简介与前言
CS224d是斯理福在今年春季开设过的一门课程, 全称deep learning for natural language processing, 顾名思义, 是使用最近的深度学习来做自然语言的一门课程, 自从上次在读书会讲过memory network之后, 结合自己之前的兴趣, 终于算是给自己找到了一个比较感兴趣, 而且又有些前景的方向, 正好和这门课的目标方法完全契合, 于是跟之.
第一周概述了deep learning和之前的方法和不同, 基本来说, 大意就是使用向量来表示一切, 之前的确定性推断全部让位给向量表示的不确定性推断, 在课程的slides中有这位一句话:
Combine ideas and goals of NLP and use representation learning and deep learning methods to solve them
以此可知, 所谓deep learning for nlp, 可能更多的是指利用deep learning的feature learning的能力, 将之前自然语言中难以表达, 无法表达的概念用更好的vector来表示出来, 从而可以使用其他的机器学习或者神经网络的手段来进行处理.
举例来看, 之前我们看到一个句子, 在进行句法分析的时候, 需要借助已经标注好的词性来进行句法的递归分析, 如下图所示(此处不是很确定, 对传统nlp还不是很熟, 待补充):
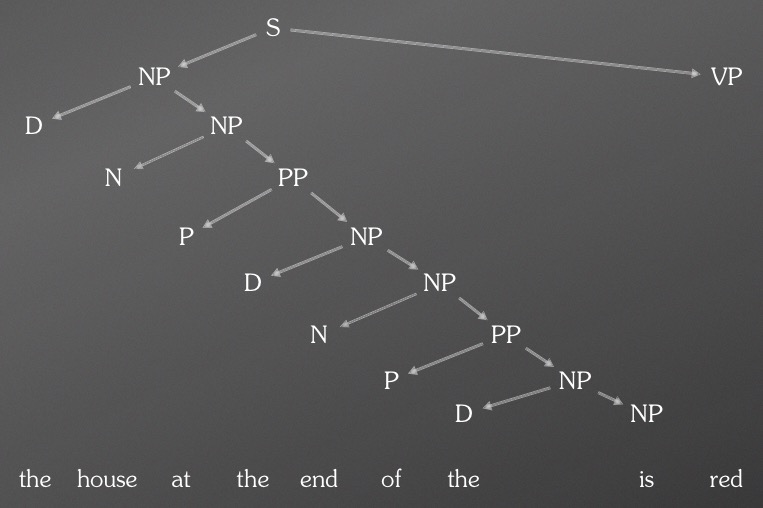
而使用dp的做法, 则是将每个词都视为一个向量, 然后使用神经网络来对向量进行组合, 加乘等等操作.
这样做的好处在于, 在之前的做法中, 一个词就是一个词, 词在语言中的意义是完全没有办法表示的, 而把词视为向量之后, 就可以通过一个向量在向量空间中的相对距离, 来潜在地把主义相互关系等等编码进来. 这其中的差别, 在之后更多地遇到具体地实例时, 将会结合实例来进行更详细地讨论.
向量空间模型.
第一周的任务, 除了简单的课件和讲义之外, 主要是包括一篇论文from frequency to meaning, 在这篇论文中, 作者将向量空间模型(vector space model)进行一个全面的综述, 并提出一种新的归类框架.
向量空间模型, 就是把自然语言中的一些频率信息(这是根据文中的定义来的, 实质上, 组织矩阵并不一定通过频率统计的形式)以矩阵的方式表示出来, 而矩阵的第行每列分别用不同的归类方式来组织, 这样每行每列都是所谓的向量.
向量空间模型最早在1971年由salon提出, 当时实现了SMART系统, 这个系统可以看做现在搜索引擎的先驱, 其中的term-document matrix, 到现在也仍然是大部分搜索引擎的基本实现方式.
同时在近年来, 随着对这个模型的一些扩展, 也实现了一些有趣的效果, 比如作者06年用这个模型来做SAT测试中的多选类比题, 取得了56%的准确率, 而人做这类测试的准确率是57%.
92年, rapp同样用这个模型, 在托福考试的多选同义词题, 取得92.5%的正确率.
对于向量空间模型而方, 我之前曾经使用term-document matrix进行过文本分类, 当时读paper, 所有的例子都是term-document matrix, 便以为vsm就等于term-document, 现在看来全然不是这么回事, 近来词向量word2vec的一些思想, 其实早到九十年代初, 就有人开始提出使用word-context的形式来组织矩阵, 从而对词的潜在语义进行编码.
拿最简单的模型term-document来说明这个vsm大概是什么, 做什么用.
假设你现在到了一个图书馆, 你看到四本书, \<老人与海>, \<规训与惩罚, \<机器学习—一种概率视角>, \<计算机系统—程序员视角>, 于是你开始闲得无聊, 数这本书中每个词出现的词, 于是你得出了下面这个矩阵:

也就是说, 在老人与海中, “独自”这个词出现了8次, 在\<计算机系统—程序员视角>中”权力”这个词出现了1次, 以此类推, 这里行名是对应的书名, 而列名则是一个词, 于是, 很简单的计数, 就可以得出这个矩阵, 当然实际一个图书馆的矩阵要比这个要大得多.
于是在这个矩阵中, \<老人与海>这本书就可以使用\<8,0,3>这样一个向量来表示, 通过这种表示, 就可以通过两个向量在向量空间中的距离计算来得到两本书的相似性.
搜索引擎的做法就是将你输入的query, 与已经索引好的文档的其他向量进行距离计算, 然后给出最相似的文档.
而这样表示的时候, 不仅书表示成一个向量, 词也可以表示成一个向量, 同样的思路运行在词上, 就可以来对词的相似词进行计算, 进而捕获词与词之间的同义, 上位, 下位等等关系.
今天先到这里, 下次继续.