接触这个领域的时间并不长,到现在也称不上入门,但是也有些经历,也许说出来可能给相同阶段的童鞋们一些借鉴。
关于学习的动机
为什么在这样一篇谈学习线路的文章里要首先谈学习的动机,原因在于学习或者说工作和职业在深入之后希望做出一些成果的话都仍然是一件非常需要投入的事情,没有这样的动机,hinton, lecun等几位大神不可能在神经网络几次陷低谷的时候仍然在这个领域深耕并推动这个领域的发展。
我在接触AI之前兴趣非常驳杂(现在也并没有好多少),在人文社科和自然科学领域都有一点接触,于是很长时间内,在各个领域之间跳来跳去,遇到Ai之后,感觉到这门学科的思维范式以及跨领域性可以把之前对计算机,心理学,经济学,哲学的非常多的思考贯通起来,而且这门学科中的很多内容都是如此好玩,因此才确定入坑.
关于学习的路径
我的学习路径是这样的:
<用nltk进行自然语言处理(书籍)> —> <cs181.1伯克利人工智能课程> —> <coursera斯坦福机器学习课程> —> <cs229,斯坦福机器学习讲义> —> <一个文本分类的project> —> <统计学习方法 李航> —> <PRML> & <cs224d 斯坦福自然语言处理课>
这其中也读了不少论文, 看了不少的博客和技术文章, 跟了不少的小项目, 但是都比较零散.
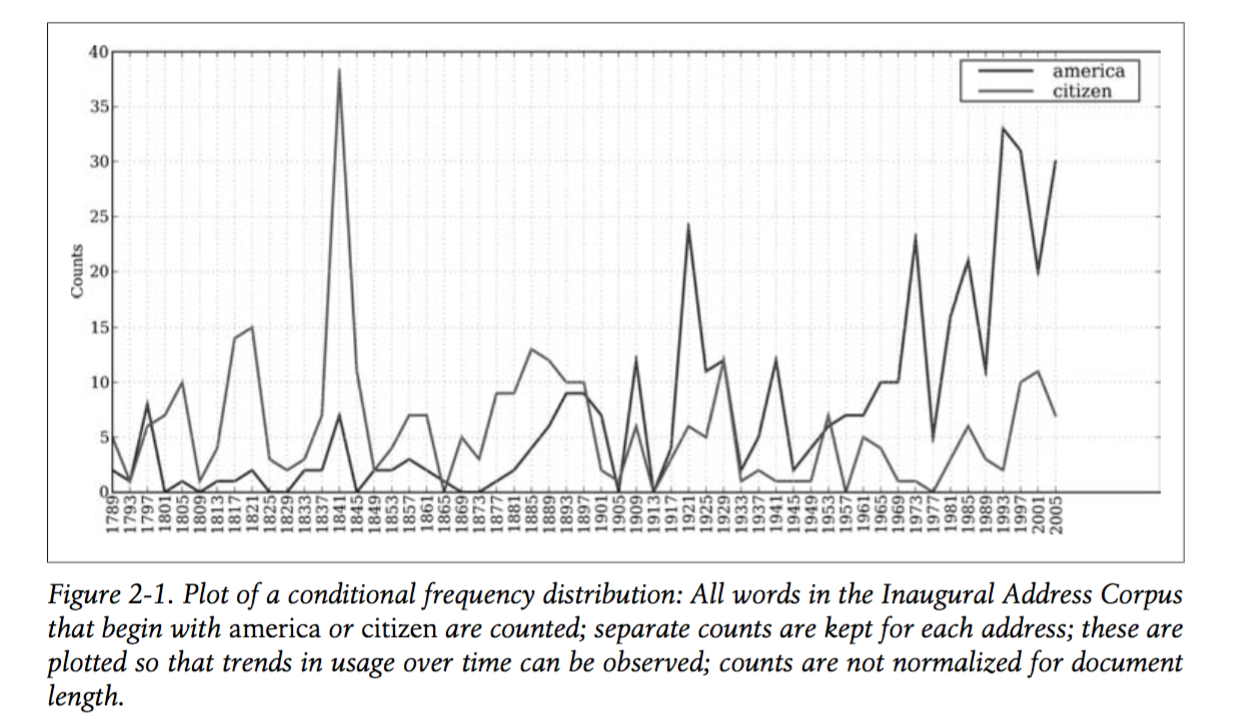
这本书当时读主要作用是打下了python编程的基础, 我是从这本书开始接触python的, 关于机器学习的语言问题, 从现在看来, java、python、scala、R、c-plus-plus应该是之后主要的几门语言, 其中java和c-plus-plus偏向工程化应用, scala主要是spark这个工具带起来的, R纯研究目的, python则跨研究和工程两大类, 可用的包最多, 语法简单易上手, 算是刚开始入坑的不二之选; 另外这本书中顺带也讲了自然语言处理的一些基本方法, 课后题中有很多的非常不错的小题目. 大家可以参照一看.

<cs188伯克利人工智能课程>
需要重点推一下这门课, 这门课给出整体的框架, AI都有哪些主要问题, 主要的学科范式是什么, 如何对一个问题进行建模, 我当时学习的时候, edx平台只有前半部分, 现在已经是完全版的archive.
这门课也是我在跟过的公开课中体验最好的一次, 当然时间的投入也比较长, 作业相对难一些.这门课最好的地方在于, 它的作用从前到后, 几乎是在一个一个大的游戏项目的框架下进行的, 跟着课程一步步走, 能够较快地进入到一个大型项目的协同开发的路子上, 这种经验是非常可贵的, 相比之下, cs229的课程作用使用的大多是matlab代码, 几个文件解决一个理论问题. 从实践性到深入程度与这门课都不可相提并论.
上图就是这门课强化学习的一个作业, 基于强化学习做的pacman小游戏, 其中pacman的行为完全是通过强化学习在随机经验中学习出来的. 图不太清楚, 大家凑合着看吧.
coursera ng课程与cs229讲义
这两个可以放在一起说, 因为都是ng的东西. 吴恩达童鞋的coursera课程应该是机器学习入门最多的推荐了. 吴童鞋的讲课实在是深入浅出, 把一个东西讲得非常透彻(曾经听过吴童鞋演讲, 他初任教职的时候讲课全校排名倒数, 不得不感叹人要用心做一件事, 也是耶风挡不往)
ng课程的内容大家说得够多, 顺便推一下cs229, cs229的比coursera课程要难了很多, 更偏理论推导, 而且会讲到线性指数族, 强化学习, EM算法等等更多更深的内容, 由于和cousera课程的内容有一部分重合之处, 和coursera课程参考着看更好, 而且有概率,线代,高斯等等补充材料. 也方便快速地过一下基础.

如果这门课能够好好地刷完的话, 机器学习就算是入门了. 整个领域的方法论就算完全掌握了, 掌握的好的话, 独立完成一些项目就没有问题了. 去各大公司面试什么的, 应该也是OK.
PRML & 统计学习方法
这两本书也放在一起说了, 需要说的是这两本书, 我还没有读完, 但是啃PRML应该是每个有志于机器学习的童鞋必须要做的一件事, 此书确实非常经典, 但是也非常难啃, 具体应该如何啃, 方法放到后面说.
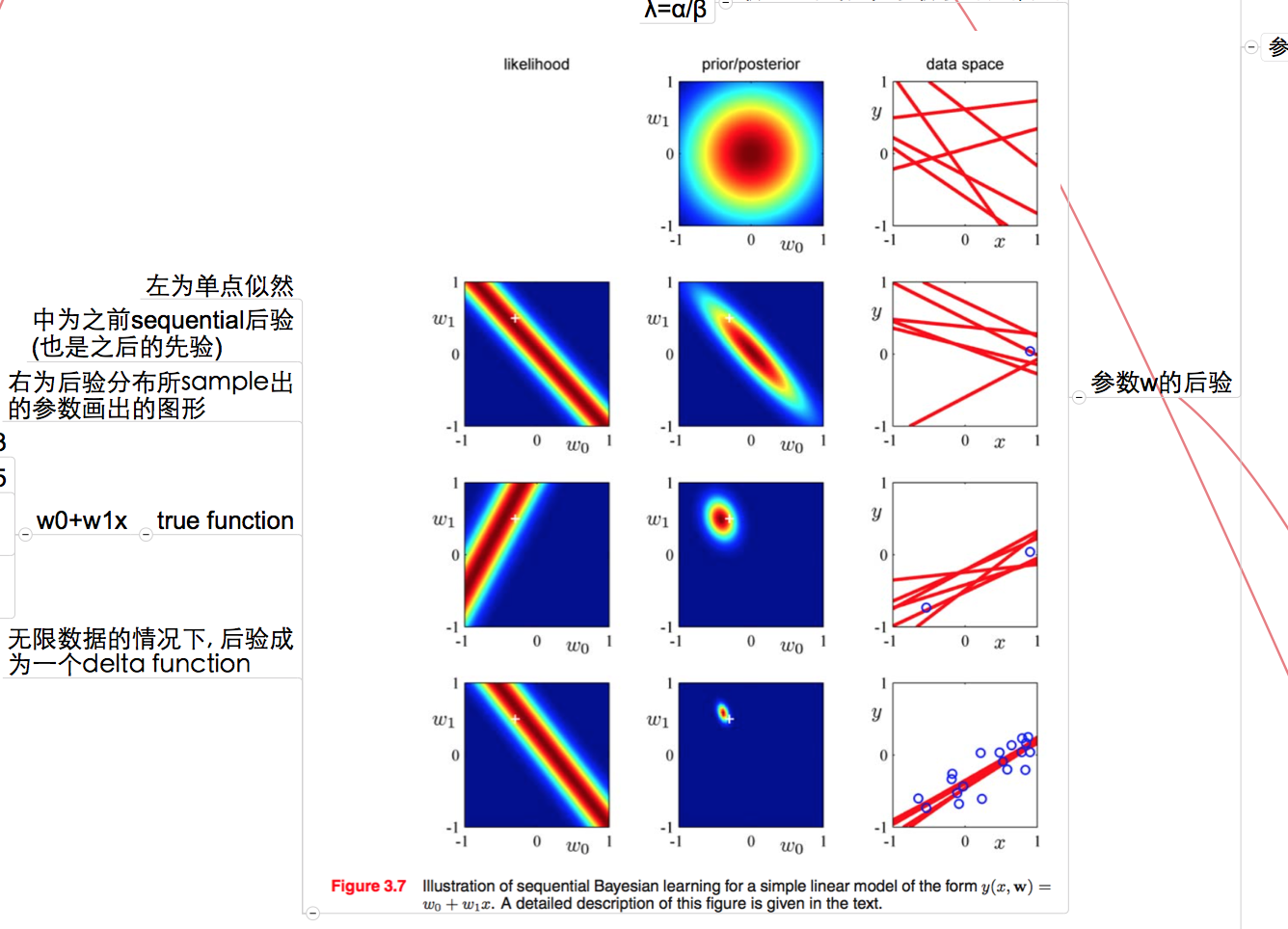
对于统计学习方法而言, 这本书写作的方法更像我们之前读过教科书, 非常的简洁, 但是李航老师对这些问题的讲解仍然清楚, 虽然是薄薄的一本小册子, 料却十足. 最近写knn, 优化的时候, 仍然是从这本书的kd树中得到的思路.
cs224d
这个已经是自己的研究方向了, 比较个人化, 只捎带提一句就好.
提一下深度学习, 深度学习近两年非常火, 机器学习和深度学习的关系到底应该怎么摆, 是否有了深度学习就可以不用机器学习了? 想必是一些人心中的疑问.
其实我对这个问题并没有多少发言权(毕竟入行时间不长), 但是从个人体会出发, 深度学习从长远来看必然会发挥越来越大的作用, 但是即使它解决了表示的问题, 在实际工作中, 大量的任务, 还是需要使用机器学习的方法来进行探索, 聚类, 简单的分类, 特征工程, 无论是在哪个任务中, 出现的频次都非常高, 而这些活如果都使用深度网络来实现, 其代价和成本实在是太大, 而且深度学习的模型本来是比较复杂的, 数据量如果不大到一定程度, 使用深度学习并无必要而且容易过拟合.
关于学习的一点心得.
从接触这个领域到现在, 算算已经过了两年半的时间, 除去中间被各种事情打断的时间, 自己的学习和工作应该已经有近两年, 但是对于这个领域仍然不敢说是入门, 主要在于这个领域每一个点的背后都是有着数学支撑的, 到底怎样算是对机器学习入了门呢, 拿到一个问题, 能够找到合适的算法包解决它? 能够架设一个分布式平台实现大数据规模的机器学习? 能够优化模型, 在数学上优化新算法? 上述每一个问题都需要长期扎实的学习和钻研.
一个最大的想法是:
一定要在代码, 工具, 数学, 论文之间找到一个平衡. 这个领域吸引人的东西很多, 像vanpik这样的数学家和jeff dean这样的工程之神都在这个领域中, 中间更有ng, hinton这样的人物, 这些大神们的背景也正像黑客与画家一书中所谈的那样, 计算机是个框, 什么都可以往里装, 工程师, 数学家, 黑客, 计算机科学家看起来好像都是同一个title, 在相似的title之下, 找准自己的定位的长期的发展方向是非常必要的.
但是同时, 如果要实现什么东西, 无论是优秀的工程实践也好, 牛叉的科研成果也罢, 工程能力和学术能力都是需要的, 无非是这两者之间的谁多谁少的平衡问题.
所以在学习时, 从一个算法的数学证明, 到复杂度计算, 到算法的实现, 到工具平台化的抽象, 这几个部分也需要一个平衡和侧重, 建议是在学习的时候, 也能够从几个不同的点来学习.
举例来说, 对于knn, 掌握knn的数学证明, sciki-learn中的包使用, kd树的优化方法, 能够分析其算法复杂度(例子不太好…), 这样间杂着学习, 理论和实践相互替, 才能够更地对这个算法有比较透彻的了解, 同时也需要对数据集的数据特性做一些探索.
写在最后
我入行不久, 造诣也并不算深, 厚着脸皮写下这篇文章, 无非是想也许正好有处在相似阶段的童鞋确实想入坑, 那么这篇文章也许能够有一定借鉴作用.
借用ng童鞋的话, ai是一门回报非常大的学科, 无论是对机器的认识, 对人自身的认识, 对自然问题的认识, 甚至人的存在本质, 自由意志, 都可以在门学科中得到更深入的洞见和收获.
更何况, 它还是一门新生的学科. 五十年历史过去, 却连学科(人工智能)的定义都没有, 这个天地也是大为可为. 期待与大家一起努力.