适合读者:对word2vec有概念上的了解, 希望有细节上的掌握以及更深一步理解的研究人员, 工程师。
早先和人聊天,曾经聊过一次自然语言方面深度学习方法的发展和影响, 虽然从word2vec之外,nlp的神经网络方法也已经成为业界的主流, 但是与图像, 语音等领域相比, 始终还是差点意思,christopher maning在CS224N中提到语言是不同于图像, 语音的信号系统, 可以认为是一种符号\类别\离散系统。
想想也是,一般来讲都认为, 语言是人类独有高级认知系统, 语言之秘似乎就代表着人工智能中最艰深的问题。
在我自己看来,深度学习在自然语言领域最重大的贡献,word2vec算一个, 这个工作直接给后续一系列的任务奠定了基础, 甚至说是起到了改变研究范式的作用也不为过。
seq2seq算一个, 这个工作直接让机器翻译等等序列标注问题有了一个能用的框架, 而且将把这个问题推向了应用化。
除此之外, 虽然领域中各种模型层出不穷, 但是论影响力的广度和深度, 以及从思想上来讲的深刻性, 似乎都差着一星半点。
最近刷emnlp, 看到emnlp2017又有一些很有趣的在word embedding上作文章的paper, 于是就想把这个方向的一些成果和研究梳理一下。
word2vec.
word2vec由mikilov于2013年提出, 虽然之前已经有了一些关于词的向量表示的工作, 例如使用svd分解, 但是其效果都不太好。
word2vec包括两个算法, skip-gram和CBOW, 其基本思想是一个词的意思, 可以由这个词的上下文来表示。 相似词拥有相似的上下文, 这也就是所谓的离散分布假设(distributional hypothesis)。
术语定义, 例如一句话, “I want to go home”, 中心词为”to”, 上下文词为”I”, “want”, “go”, “home”。
对于skip-gram来说, 我们是通过中心词来预测上下文词的概率。对于CBOW来说, 我们是通过上下文词来预测中心词的概率 。
CBOW
初始化
拿到一篇文章, 先扫一篇文章, 建立辞典, 然后将辞典中的所有词进行初始化, 初始化为一个N维向量(实际使用中, 300到500不等), 这样得到一个d * |V| 的一个矩阵, 重复这个操作, 得到一个同样size, 但是不同值的矩阵。这是因为在word2vec中, 对于输入的embedding和输出的embedding使用不同的编码, 由于同一个词, 即可能是上下文, 又可能是中心词, 故而做此处理。
训练
输入: 以相临的5(即所谓的滑动窗口, 窗口大小为超参数 ,可设)个词为一个样本, 那么上下文就是第0, 1, 4, 5个词在词典中的索引, 假设这个索引为7, 12, 6, 8.
输出, 一个|V|* 1的概率向量, 每个位元表示中心词正好是这个辞典中这个位置的词的概率。例如在辞典中第三个词为”absorb”, 那么p3=0.017, 就表示模型认为中心词为absorb的概率为0.017.
过程,拿到输入上下文的索引后,在输入embedding矩阵中查表, 得到第[7, 12, 6, 8]列,于是我们得到了四个向量,然后将这四个向量进行平均, 得到一个context vecter.
再取到输出embedding矩阵中中心词的向量, 在这个例子中, 假设中心词”to”在辞典中的第1487位, 那么就取输出embedding矩阵中第1487列。 求这个向量和content vector的乘积, 将这个乘积在所有词上做softmax.
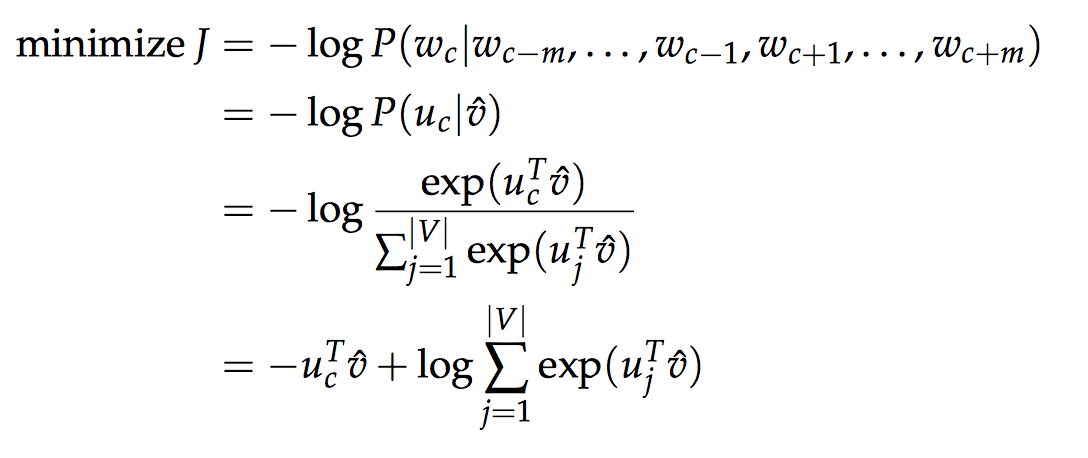
如上图所示, 其中m为2, 也就是滑动窗口size的一半减1,wc代表中心心词, 第一行是指, 我们需要在给定上下文的情况下,最小化中心词的条件概率。
第二行, 我们将上下文使用输入embedding矩阵向量化并求平均, 将中心词使用输出embedding矩阵向量化。
第三行, 表示其在整个辞典上建模的softmax概率。
回顾一下整个思想, word2vec的想法是, 使用一个(准确来说是两个)高维向量空间来对词进行建模。 每个词即为向量空间中的一个点。 使用向量的dot product来衡量两个点之间的距离, 然后根据这个距离来最大化条件概率。
在这个模型中, 两个embedding矩阵为参数, 最后求一个最大似然, 也就是最小化其negative log likelihood。
skip-gram
skip-gram模型与CBOW相似,不同在于, skip-gram是使用中心词来预测上下文的词。
惟一值得注意的是, 中心词只有一个, 而上下文的词有四个, 那么如何建立这种一个对四个的对应关系, 在这里mikolov使用的是朴素贝叶斯假设, 也就是认为在给定中心词的情况下, 上下文词之间是相互独立的。
于是我们有这样的结果:
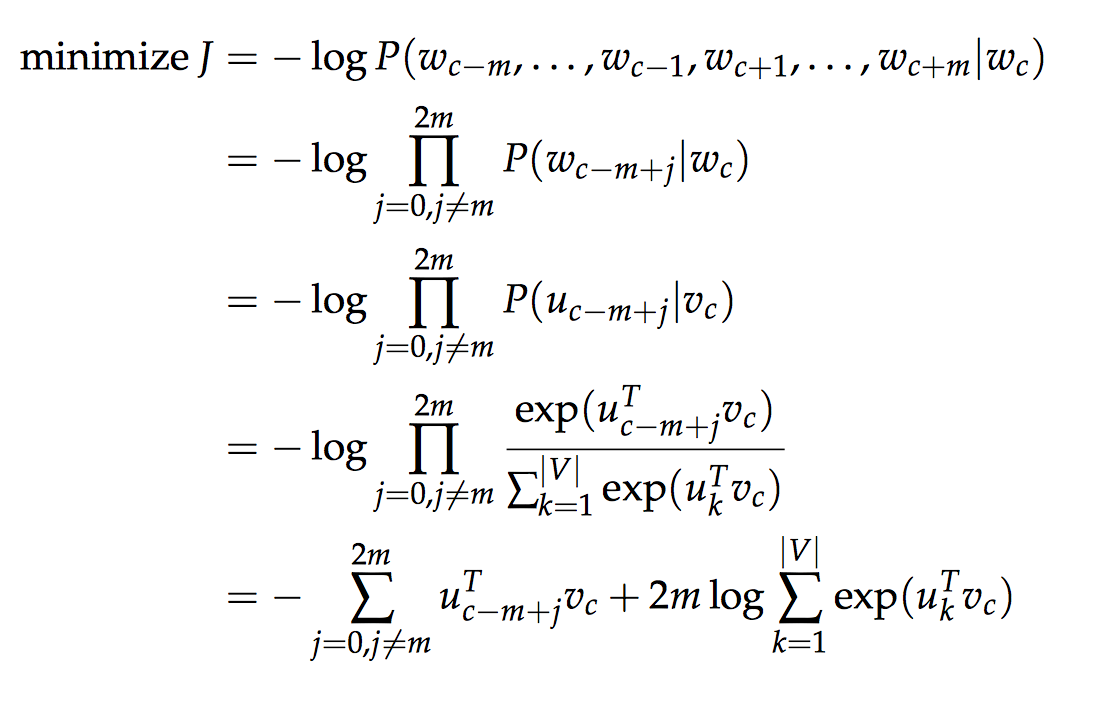
negative sampling
上面两个公式在实际计算的时候有一个问题,因为最后我们是对整个辞典上求softmax, 那也就意味将, 每过一个样本, 我们都要在整个辞典上算一次全部词向量和当前中心词的点积。 这个计算量太大了。
因此, 在论文中, 使用negative sampling这样一个技巧来处理这个问题。
其思想就是, 我们做一个负样本, 可以理解成随机语料, 于是每次训练的时候, 我们就有一个正样本和若干个负样本,我们让正样本的预测概率尽可能大, 而让负样本预测概率尽可能小, 通过负样本的引入, 将本来建立在整个辞典上的一个|V|分类问题, 转换成一个建模在正负样本上的一个二分类问题。 具体来说:
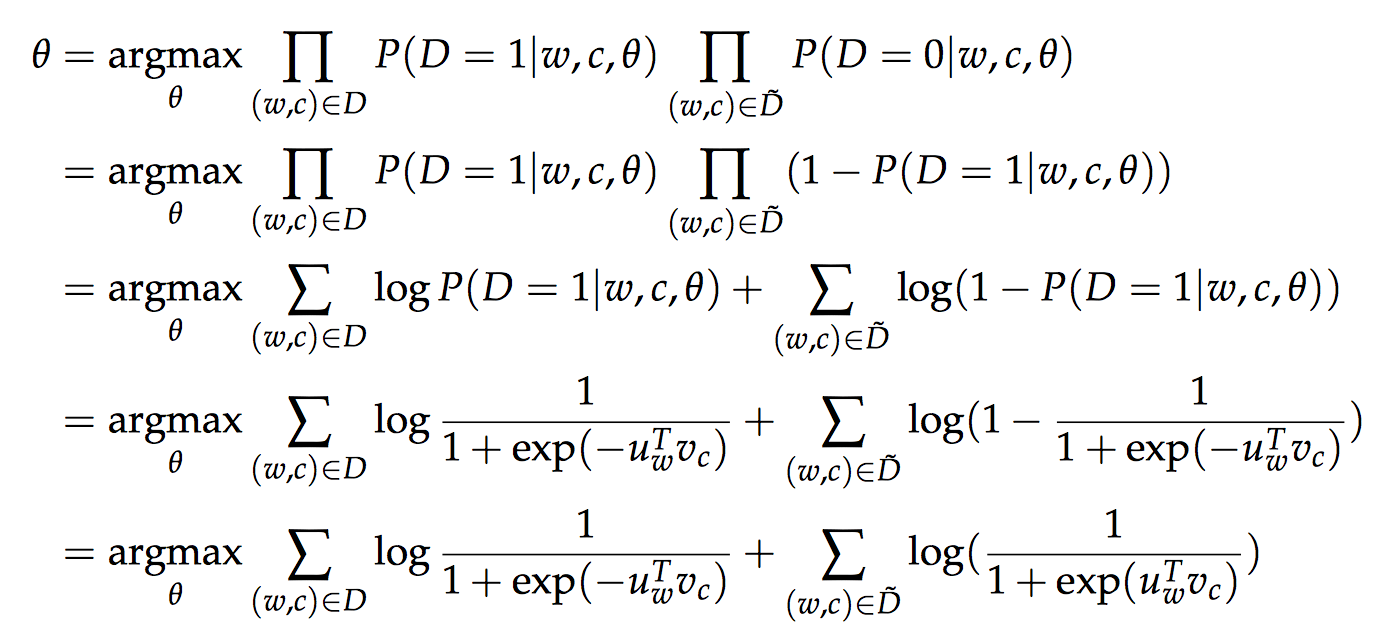
如上图, 当D等于1时, 即样本来自于真实语料, 当D等于0时, 样本来自于随机语料, 我们要使如果样本是真实样本, 那么概率就尽可能大, 如果样本来自随机语料, 那么概率就尽可以小(也就是D=0尽可能大)
这种转换中中涉及到一个很有意思的点, 就是softmax多分类概率和sigmoid二分类概率的等价性, softmax即是sigmoid, 参见CS229.
在生成负样本时, 我们使用Pn(w), 也就是决定要不要sample出某个词作为负样本,使用Pn(w)=freqency^(3/4)
即以词的unigram频率的3/4次方。
其意图是:
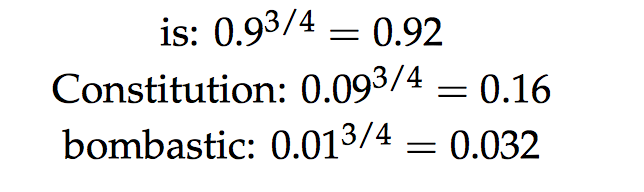
于是像is这样的高频词,在处理之后, 生成的概率还是较高, 但是变化不大, 而像bombastic这样的低频词, 其生成的概率就提高了三倍之多。
word2vec还使用Hierarchical Softmax来解决softmax计算量过大的问题, 思路是将词典挂在一棵哈夫曼树的叶结点上, 然后将一个词的softmax, 转换为这个词与这棵树上从根结点到词的父结点每个结点向量的点积的方向加权的sigmoid乘积。 这里就不多说了。
word embedding与矩阵分解的内在一致性
2014年, Yoav Goldberg在其《Neural Word Embedding as Implicit Matrix Factorization》 分析得出结论, word2vec其实质就是对语料的word-context的PMI矩阵进行分解 ,让我们来仔细看看这个过程:
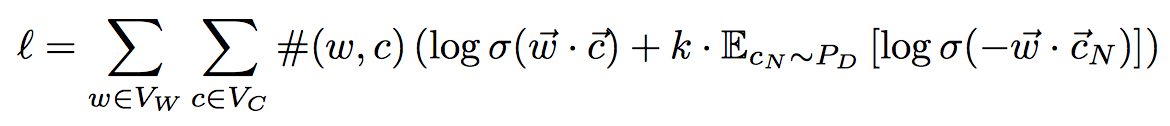
上图是skip-gram同时进行negative-sampling之后的损失函数, 其中w为中心词, c为上下文, 这个损失函数是定义在整个语料上的(也就是跑完一个epoch), 因此要对中心词和上下文都进行求和符运算,k是指对于一个中心词进行多少次negative-sampling, 生成多少个负样本,Cn为negative-sample出来的负样本的上下文词。#(w, c)是指一个(w, c)的词对,在语料中出现的次数。
假设在真实语料由三句话组成, 分别是”what i am”, “fine. but what is that”, “so Lucy, what are you doing about”, 那么what作为中心词就只有两次,分别是
样本1: “.” “but” “what” “is” “that”
样本2:”Lucy” “.” “what” “are” “doing”
在以what作为中心词时, 我们negative sample出这样一个句子:
样本3:”about” “am” “what” “fine” “is”
作为上下文词,what出现1次, 分别为:
“what” “are” “you” “doing” “about”
公式1
![]()
我们进行第一次变换, 第一行只是简单地把求和符拆开, 第二行之所以可以进行如此变换的原因是因为在negative sampling的时候,是针对每一个中心词来做的, Cn的次数生成只与Pd也就是negative-distribution有关, 所以第二项对于c来说是个常数, 于是sum(#(w, c)) when c belong to Vc, 就等于#w, 这里#符号代表着在语料中的计数。
公式2
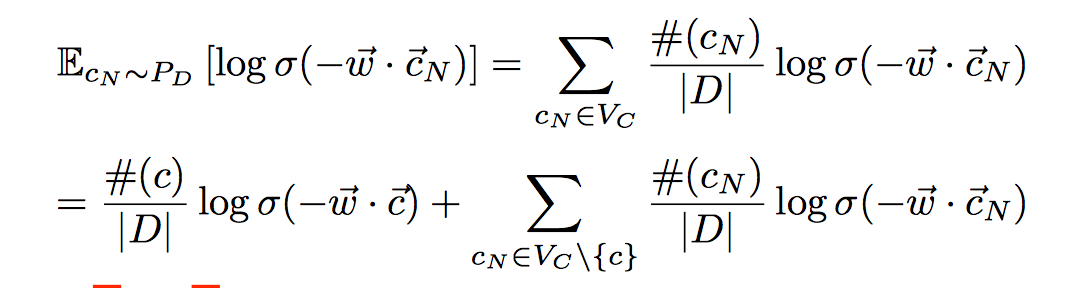
我们把注意力集中在公式1的第二部分, 进行再一步的变换, 在这次变换之后,negative-distribution的期望写成其分布原本定义的形式, 这里的Pd, 就是上面negative-sample小节中的Pn, 注意在这篇论文中为了简化起见,Pd, 直接用了基于频率的unigram distribution, 和mikolov的原文不太一样, 不过这里并不影响最终的结论, 只需要把这个#(cN)换成#(cN)^(3/4)就可以了。
这个变换的意思, 是指将negative-sample出来的上下文做一个更细的区分, 将那些正好在真实语料的上下文词集合中出现过的上下文词写出来做为公式的第一部分,在这个例子中, (“what”, “is”)句对, 就属于即在真实上下文, 中心词对中出现过, 也在negative-sample中出现过的应该, 归到上面公式的第一种部分, 而(“what”, “fine”)就属于只存在于negative-sample中的情况, 应该归到公式中的第二部分。
将上面的公式1和公式2合并, 得到如下的变换:
![]()
也就是说, 现在我们暂时只考虑在语料中出现过的(w, c)词对。对于这种词来把loss单独写出来。也就是只考虑(“what”, “is”)这样的词对。令x = w . c, 然后再求偏导
![]()
就得到了上面的式子。
然后再令这个式子的偏导为零, 很容易能够求得:
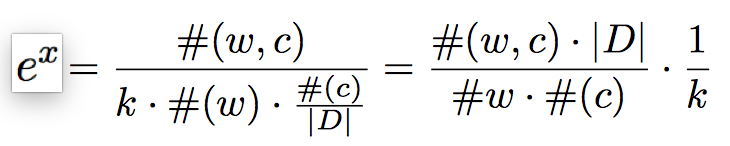
最后, 把式子拆开, 就得到了。
![]()
这里就非常有意思了, 在第一个对数符号里包的那一堆东西, 恰恰就是广为人知的point-wise互信息公式。
最后我们来回溯一下, 在skip-gram中, 我们学到了两个矩阵, 输入embedding矩阵和输出embedding矩阵, 分别用来编码中心词和上下文词, 我们在skip-gram的原始形式中, 做向量的点积, 然后用这个点积来做softmax, 在做点积时, 我们实际就是取了, 这两个矩阵的某一行和某一列, 做点积, 那么如果把输入embedding矩阵表示为W, 输出embedding矩阵表示为C, 我们就得到了这样的结果:
![]()
也就是说, skip-gram模型的实质, 其实就等同于, 我们拿到了语料之后, 先进行了一个全局扫描, 然后建立了一个行为W, 列为C, 每个位元的值为PMI(w, c)的这么一个矩阵, 然后对这个矩阵进行全局减log(k), 这里k就是negative-sample时的次数(在这个例子中k=1), 就得到了一个矩阵M, 我们对这个M进行分解, 分解之后的W, C, 就是我们所谓的词嵌入矩阵, 或者称谓为lookup table.
参考文献:
Turney, P. D., & Pantel, P. (2010, March 5). From Frequency to Meaning: Vector Space Models of Semantics. arXiv.org. http://doi.org/10.1613/jair.2934
Levy, O., & Goldberg, Y. (2014). Neural Word Embedding as Implicit Matrix Factorization. Nips.
Mikolov, T., Sutskever, I., 0010, K. C., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. CoRR Abs/1003.1141, cs.CL.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013, January 17). Efficient Estimation of Word Representations in Vector Space. arXiv.org.
https://web.stanford.edu/class/cs224n/lecture_notes/cs224n-2017-notes1.pdf